※ 이 글에서 다룬 기반기술, 프론트엔드, 백엔드, 데브옵스 등 풀스택 개발 지식은 모두 한화시스템 Beyond SW Camp 12기에서 배운 내용을 복습한 것입니다.
재난 복구 계획 (DRP : Disaster Recovery Plan)
현대의 기업 환경에서 데이터의 안정성과 가용성이 매우 중요하다.
예를 들어 기업의 데이터베이스 서버가 있는 데이터 센터가 불이 난다면 어떻게 될까? 그러면 해당 기업의 서비스가 중단될 것이다.
이러한 상황을 방지하기 위해 재난 복구 계획(DRP : Disaster Recovery Plan)이 있는 것이다. 이 계획은 서비스 중단을 최소화하고 데이터 손실을 방지하는 필수적인 전략이다.
1) Mirror Site (미러 사이트)
주 센터와 동일한 수준의 데이터와 시스템을 원격지에 구축하고 Active 상태로 실시간 동시 서비스를 제공하는 방식
2) Hot Site (핫 사이트)
주 센터와 동일한 수준의 데이터와 시스템을 원격지에 구축하여 Stand-by 상태로 유지하며 재난 발생 시 Active 상태로 전환하여 서비스 제공
3) Warm Site (웜 사이트)
데이터만 원격지에 보관하고 서비스를 위한 시스템은 확보하지 않거나 최소한으로만 구성하고 재난 발생시에 필요한 시스템을 구성하여 복구
4) Cold Site (콜드 사이트)
최소한의 준비만 해두는 것
HAProxy로 데이터베이스 서버 분산
우선 HAProxy로 데이터베이스 서버를 분산을 하기 위해선 2개 이상의 데이터베이스 서버가 있어야 한다.
https://taeh00n.tistory.com/entry/%EB%A6%AC%EB%88%85%EC%8A%A4-mariaDB-%EC%84%A4%EC%B9%98
[리눅스] mariaDB - mariaDB 설치
※ 이 글에서 다룬 기반기술, 프론트엔드, 백엔드, 데브옵스 등 풀스택 개발 지식은 모두 한화시스템 Beyond SW Camp 12기에서 배운 내용을 복습한 것입니다. mariaDB● mariaDB : 데이터를 저장하고 관
taeh00n.tistory.com
위 글과 같은 방식으로 mariaDB 서버 두개를 생성을 한다.
https://taeh00n.tistory.com/entry/%EB%A6%AC%EB%88%85%EC%8A%A4-HAProxy
[리눅스] HAProxy (부하 분산) 설치
※ 이 글에서 다룬 기반기술, 프론트엔드, 백엔드, 데브옵스 등 풀스택 개발 지식은 모두 한화시스템 Beyond SW Camp 12기에서 배운 내용을 복습한 것입니다. 트래픽이 몰려서 서버가 느려지거나
taeh00n.tistory.com
위의 글은 80포트를 사용하는 nginx 웹 서버를 부하 분산을 했었다.
nginx때와는 조금 다른 부분으로 3306포트를 사용하는 데이터베이스로 분산을 하는 것이다.
우선 root 권한으로 HAProxy 설정 파일을 수정한다.
vi /etc/haproxy/haproxy.cfg
가장 아래줄에 아래와 같은 코드를 추가한다.
listen stats
bind *:9000
mode http
option dontlog-normal
stats enable
stats realm Haproxy\ Statistics
stats uri /stats
listen mariadb
bind :3306
mode tcp
balance roundrobin
server db1 [첫 번째 DB 서버 IP]:3306 check
server db2 [두 번째 DB 서버 IP]:3306 check

모니터링 페이지에 DB 서버 두개가 정상적으로 분산되어있는 것을 확인할 수 있다.
데이터 백업 및 복구
우선 Master - Slave를 적용하기에 앞서 snapshot을 하는 것을 추천한다.

스냅샷(Snapshot) : 가상 머신의 특정 시점 상태를 저장하는 것
서버를 구축하며 오류가 발생할 수도 있기 때문에 원래 상태로 복구하기 위해 스냅샷을 했다.
DB 서버를 분산할 HAProxy, 분산을 시킬 DB 서버 두 개 모두 Snapshot을 했다.
이제 오류가 발생해서 되돌리고 싶을 때 지금 설정해놓은 Snapshot을 하게 되면 모든 과정을 실행하기전인 지금 상태로 되돌아온다.
DB1 서버에 있는 것을 DB2 서버로 옮겨보겠다.
백업은 데이터베이스를 마스터 서버에서 복제 설정 전에 슬레이브 서버로 이동시키기 위해 필요하다,
mysqldump -u root -p --all-databases > backup.sql위 명령어를 실행하면 backup.sql이라는 SQL 파일이 생성된다. 마스터 서버에서의 데이터베이스 전체 내용을 담고 있고 나중에 슬레이브 서버에 복원하는 데 사용된다.
cp [원본파일] [복사받을 파일]리눅스 명령어를 공부를 해봤다면 위의 cp 명령어는 본적이 있을 것이다. cp 명령어는 로컬에서 복사할 때 사용하는 것이고 서버간에 파일을 복사받으려면 어떻게 해야할까?
그때는 scp 명령어를 사용하면 된다. scp는 파일을 원격 서버로 복사할 때 사용하는 명령어이다.
scp ./backup.sql test@[복사받을 서버의 IP주소]:/home/test/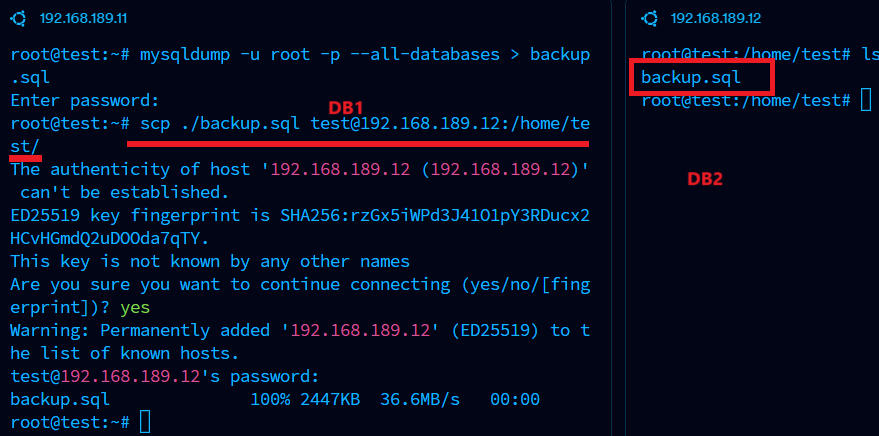
scp 명령어를 실행하면 위에서 생성한 backup.sql 파일이 원격으로 DB2에 복사된 것을 확인할 수 있다.
만약에 원격 서버의 파일을 가져와서 복사를 하려면 아래와 같이 하면 된다.
scp test@[파일 가져올 서버의 IP주소]:/home/test/backup.sql ./Master - Slave 적용 (Active - Passive)
Master & Slave 설정
vi /etc/mysql/mariadb.conf.d/50-server.cnf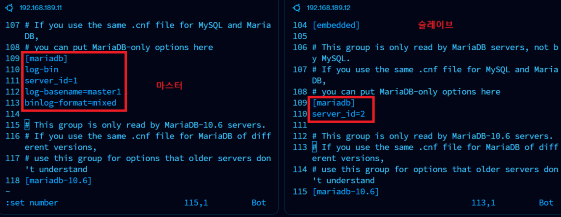
- Master 설정
[mariadb]
log-bin # 로그 활성화
server_id=1 # Master 서버의 고유 ID 설정
log-basename=master1 # 로그 파일의 기본 이름 설정
binlog-format=mixed # 로그 포맷 혼합 모드로 설정- Slave 설정
[mariadb]
server_id=2 # Slave 서버의 고유 ID 설정
복제 과정에서 오류를 피하기 위해 각 서버는 반드시 다른 server_id를 설정 해야한다.
항상 설정 파일을 수정하면은 systemctl restart mariadb로 서버를 재시작을 해주어야 한다.
이제 Master 서버에 Slave 서버가 접속할 수 있는 계정을 설정해주도록 하겠다.
mariadb -u root -p
CREATE USER 'slave_user'@'%' IDENTIFIED BY 'qwer1234';
GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%';
FLUSH PRIVILEGES;위의 코드는 Master 서버에 입력해야한다. 이렇게 되면 복제를 할 때 사용하기 위한 Slave 서버의 계정을 Master 서버에 생성해주었다.
지금까지 Master 서버와 Slave 서버를 연결해주기 위한 설정과 Slave가 Master 서버에 접속하기 위한 계정 생성과 권한 부여까지 마쳤다. 이제 Slave 서버에서 Master 서버를 복제하기 위한 Master 서버 지정을 해주겠다.
CHANGE MASTER TO
MASTER_HOST='[Master 서버 IP]',
MASTER_USER='slave_user',
MASTER_PASSWORD='qwer1234',
MASTER_PORT=3306,
MASTER_LOG_FILE='[마스터에서 show master status 했을 때 File 이름]',
MASTER_LOG_POS=[마스터에서 show master status 했을 때 position 번호],
MASTER_CONNECT_RETRY=10;
START SLAVE;아까 위에서 Master 서버를 설정할 때 로그 활성화했다. 이 로그 파일은 데이터베이스 변경 사항을 기록하는 로그 파일이다. 데이터 삽입, 수정, 삭제 등의 모든 쿼리와 트랜잭션이 기록되는 것이다. 그래서 show master status 명령어를 사용하면 로그 파일이 나타나는데 그때의 file 이름과 position 번호를 적어주면 된다.
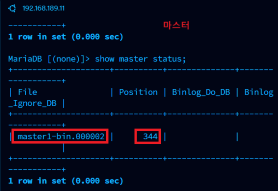
위의 Master 서버를 지정해주는 것은 Slave 서버에서 한다.
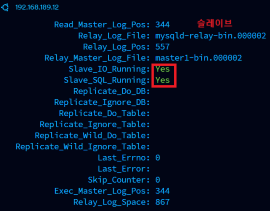
복제 설정 후 Slave 서버의 상태를 확인해보니 Yes로 정상 동작하는 것을 볼 수 있다.
그치만 이렇게 설계한 서버는 Active-Passive 관계이므로 Master 서버에서는 읽고 쓰는 작업이 가능하나 Slave 서버에서는 읽는 작업만 가능하다.
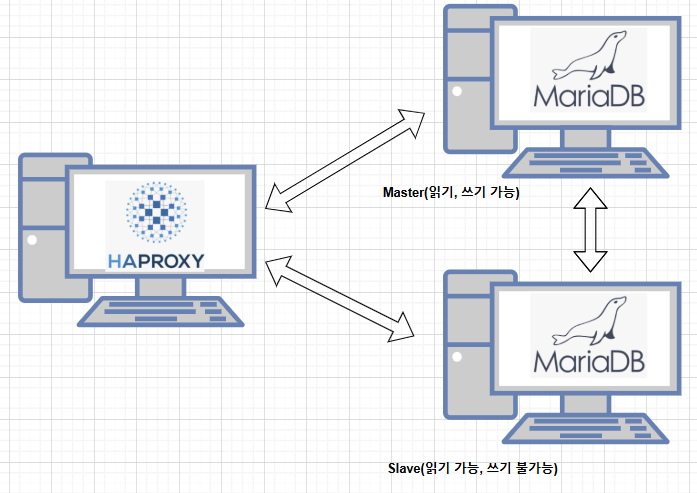
Master - Slave 적용 (Active - Active)
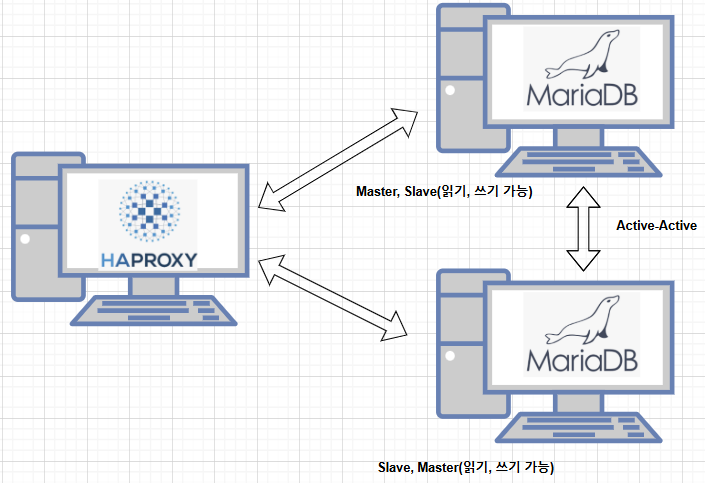
이번에는 Active - Active 방식으로 DB 서버 양쪽 모두에서 읽고 쓰기가 가능한 미러 사이트로 구현해보겠다.
위의 과정과 똑같이 진행하면 되는데 Master 서버 였던 건 Slave, Slave 서버 였던 건 Master로 양방향으로 설정을 바꿔주면 된다.
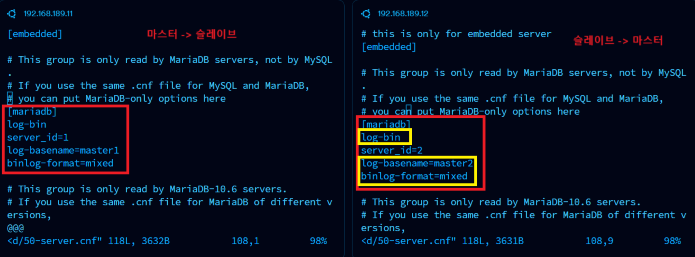
이 부분만 수정해주면 둘 다 Active - Active 상태가 될 준비가 된 것이다. 이제 양쪽 서버 모두에서 Slave를 실행해주면 된다.
나는 이미 DB1에서는 Master, DB2에서는 Slave로 실행중이기에 바로 DB1 서버에서 DB2로 Master를 지정해주고 START SLAVE; 명령어를 하면 될 줄 알았는데 Master 서버의 상태가 바꼈는지 잘되지 않았다.
STOP SLAVE;
RESET SLAVE;그래서 위의 명령어를 실행해 SLAVE를 리셋을 한 후 서로를 Master로 지정해주었다.
CHANGE MASTER TO
MASTER_HOST='[Master 서버 IP]',
MASTER_USER='slave_user',
MASTER_PASSWORD='qwer1234',
MASTER_PORT=3306,
MASTER_LOG_FILE='[마스터에서 show master status 했을 때 File 이름]',
MASTER_LOG_POS=[마스터에서 show master status 했을 때 position 번호],
MASTER_CONNECT_RETRY=10;
START SLAVE;위에서 한 것처럼 서로를 Master를 지정한 후 양쪽 서버에서 Slave를 모두 시작하니 어느 서버에서 작업하든 데이터가 양쪽 서버에 동일하게 유지되는 것을 확인할 수 있었다.
'한화시스템 Beyond SW Camp > 기반기술' 카테고리의 다른 글
| [Database] 부하 테스트 도구 (JMeter) (1) | 2024.12.03 |
|---|---|
| [리눅스] DB 분산 (Master-Slave(Hot Site) 방식) (0) | 2024.12.03 |
| [Database] INDEX, 스토어드 프로시저, View, 반정규화 (0) | 2024.12.02 |
| [Database] DB 성능 테스트 (Explain, Profiling) (0) | 2024.12.02 |
| [Database] 코딩테스트 (프로그래머스) (1) | 2024.12.01 |



